
Con la finalidad de completar lo ofrecido, ahora trataremos sobre el plugin kNN classifier, el cual emplea el método K -vecinos más cercanos, en inglés K-Nearest Neighbors Algorithm (KNN), logrando crear una nueva capa con los píxeles clasificados, además de realizar la evaluación de la precisión del proceso de clasificación. Se debe mencionar que los principios de las funciones y del trabajo del plugin están basados en el paper de la referencia 1.
Preparando los datos:
Seguiremos empleando la misma fuente de datos con la que venimos trabajando en la entrada anterior, es decir nuestra imagen compuesta del satélite Sentinel-2, del mismo modo se trabajará con nuestra capa vectorial de las áreas de entrenamiento, la cual deberá ser modificada, teniendo en cuenta los requisitos del plugin.
En resumen el plugin KNN classifer requiere lo siguiente:
- Un archivo raster multibanda con la extensión TIF, en nuestro caso tenemos una imagen del Sentinel-2 compuesta por cuatro bandas (comb2348_test.tif).
- Un archivo Shapefile que contenga un campo con la clasificación (roi_set16_test1.shp), pero además los descriptores requeridos, en este caso serán los valores de las bandas contenidos en cada uno de los polígonos (45), para lo cual vamos a emplear una herramienta ubicada en la menú raster, denominada "Estadísticas de zona".
Lo primero que haremos será aplicar "Estadísticas de zona", considerando nuestra imagen multibanda y la capa vectorial, para ello se considerará el valor de la media de cada una de las bandas.

Figura 1: Aplicando Estadísticas de zona para recopilar datos de nuestra imagen por cada banda
El proceso se repite para las demás bandas, obteniendo al final cuatro campos con los valores medios de las bandas, los que ahora serán considerados como nuestros descriptores.

Figura 2: Adición de los descriptores con valores de las bandas de la imagen raster
Empleo del KNN Classifer
Ahora podemos activar el plugin desde nuestra barra de herramientas, luego del cual nos aparecerá una ventana (Ver Figura 3), en donde dentro de la pestaña "Basic", se especifica nuestra capa raster y luego nuestra capa vectorial actualizada. Posteriormente hay que indicarle lo siguiente:
- Una carpeta de salida de nuestros resultados.
- El número de vecinos más cercanos (k), es decir el número de vectores de muestra (polígonos) más cercanos de acuerdo con la distancia.
- La selección de las bandas disponibles para ser considerados.
- Lista de los descriptores provenientes de la tabla de atributos de la capa vectorial, solo deben ser considerados los campos relevantes para la clasificación.
- El parámetro a ser clasificado, existiendo la opción de realizar una clasificación con múltiples parámetros.
- Finalmente se indica el modo de clasificación, el cual está en relación al parámetro a ser clasificado, "c" para el parámetro categórico y "n" para el parámetro continuo.
Es importante mencionar que debemos emplear la tecla "Ctrl" para realizar múltiples selecciones, como las bandas y los descriptores.

Figura 3: Configuración requerida para ejecutar el plugin kNN
Primeros Resultados Obtenidos
Luego de ejecutar el plugin en nuestro panel de capas aparecerá la nueva capa raster con el resultado de la clasificación, el cual presenta la siguiente estructura: SC_ + nombre de la imagen + nombre del parámetro + _valor de k + modo de clasificación (SC_comb2348_test2Clase_ID_3c). Luego para visualizar mejor podemos emplear el estilo que venimos trabajando.

Figura 4: Vista del resultado de clasificación con la configuración básica
También se genera un archivo de texto (.txt), con la evaluación de la precisión del algoritmo empleado con los valores ingresados, el cual se almacena en la carpeta de salida elegida. La interpretación del mismo sería:

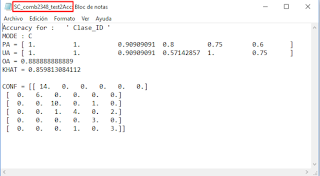
- OA: Precisión general - todos los píxeles clasificados correctamente (todos los tipos) / todos los píxeles clasificables (todos los tipos)

- PA: Precisión de los "productores" - Muestra el porcentaje de cuántos píxeles de cada tipo se clasifican correctamente. Correctamente clasificado (de un solo tipo) dividido por el número total de píxeles de prueba del mismo tipo de acuerdo con los datos de referencia. Para nuestro ejemplo se muestran seis (6) valores que corresponden a las clases consideradas.

- UA: Precisión de los usuarios - Muestra la probabilidad de que el tipo específico realmente represente ese tipo. Correctamente clasificados (de un solo tipo) / clasificados (de un solo tipo).

- KHAT: Este valor describe qué tan bien el algoritmo kNN clasifica los píxeles si se compara con el clasificador aleatorio. Por lo tanto, valores cercanos a 1 indicarán un buen desempeño del algoritmo.





Figura 5: Vista del resultado de la evaluación del algoritmo en un archivo de texto
Es recomendable ir probando valores de k distintos para ver el valor que mejor se ajusta, en este caso luego de realizar pruebas con otros valores, se comprobó que el valor de 3 es el más adecuado. Para tener otros criterios al momento de elegir este parámetro, recomiendo revisar la referencia 2.
Editando nuestra configuración para clasificar
Ahora vamos a probar algunas otras opciones que tenemos, todo ello con la finalidad de personalizar nuestra configuración inicial. Para ello, en primer lugar nos debemos ir a la pestaña "Advance", desde aquí veremos que podemos realizar algunos ajustes:
- Distance calculation: La modificación de esta opción que por defecto está marcado en "Euclidean", puede alterar la velocidad en el procesado para obtener los resultados; esto se debe a que ambos métodos de cálculo emplean distintas fórmulas, siendo la de Manhattan, la que consume menor tiempo de procesado. El principio de ambos se puede resumir si apreciamos la Figura 6, en donde podemos apreciar las fórmulas que consideran ambos métodos:

Figura 6: Representación gráfica de los métodos de cálculo de distancias (Fuente: Ref. 2)
- Mask layer: Te permite incorporar una capa raster que indique solo aquellos píxeles que deben ser clasificados, dicha capa debe contener valores de 0 (píxeles que no son considerados) y 1 (píxeles a ser considerados).
- GeoDistance: Proporciona al usuario una opción para seleccionar datos de muestra a la distancia deseada desde un píxel clasificable. Esta opción limita nuestros datos de muestra y reduce la influencia de las muestras ubicadas más lejos. La distancia se mide en kilómetros [km]. Al habilitar esta opción, el usuario debe verificar que los datos de entrenamiento tienen columnas denominadas "x" e "y" que contienen coordenadas de los puntos de datos de entrenamiento.
- Feature weights: Te permite realizar un tipo de ponderación a nuestros descriptores, por lo tanto valores mayores a 1 incrementa la significancia del descriptor; los valores deben estar separados por comas.

Figura 7: Configuración de opciones avanzadas del plugin
En resumen, tal como se aprecia en la Figura 7, se seleccionó a "Manhattan" como método de cálculo de la distancia, no se activo ninguna capa máscara, se indicó a 1 km como GeoDistance, pero al momento de ejecutar el algoritmo, se mostró la advertencia que no se cuenta con suficientes puntos de muestreo, lo cual es comprensible, teniendo en cuenta la reducida extensión con la que estamos trabajando, también se habilitó la opción de estandarización y finalmente la generación de ponderación, se le asignó mayor peso a las bandas 3 y 4, las que corresponden a las bandas roja e infrarroja del Sentinel-2 respectivamente.

Figura 8: Resultado obtenido al modificar algunos parámetros.
Si apreciamos la Figura 8, veremos que el resultado no fue satisfactorio si lo comparamos con nuestro primer resultado, esto nos permite descartar la opción de emplear "Manhattan" como método de cálculo de la distancia. Por lo tanto, si mantenemos los cambios y volvemos a emplear "Euclidean" obtendremos un resultado similar al primero, pero visualmente se comprueba que existe algunas mejoras.

Figura 9: Resultado de la clasificación empleando ponderaciones
Bueno, con esta parte cumplo con lo ofrecido, teniendo la intensión de poder mostrar otras opciones que tenemos para realizar una clasificación supervisada. Para que puedan profundizar sobre esta metodología, recomiendo revisar la referencia 3, en donde el autor del plugin explica detalladamente las características del mismo y que por mi parte traté de resumirlas en esta entrada.
Referencias:
2 comentarios:
Estimado Carlos, quisiera consultar por que estoy intentando determinar el porcentaje de superposicion entre un shapefile (que muestra zonas de areas protegidas) y un archivo asc (con valores continuos de aptitud de habitat). pero no he encontrado la herramienta adecuada en qgis. Cuando utilice intersección me dio el siguiente error
Input layer A contains invalid geometries (Feature 806). Unable to complete intersection algorithm.
mi intención es superponer estas dos capas y calcular en que porcentaje se superponen es decir que porcentaje de habitat con aptitud maximo se encuentran dentro de areas protegidas. que herramienta de qgis podría usarse? de antemano, gracias por la ayuda!saludos
Mi estimado, por lo que me indicas, al parecer tu archivo shapefile tiene errores de geometría, primero te puedo recomendar que en QGIS utilices la herramienta "comprobar geometrías", para que veas los errores existentes y se puedan solucionar. Por otro lado, el archivo raster (asc), es posible que necesites hacer una reclasificación de valores para que puedas evaluar los resultados. Ahora, los algoritmos de "intersection" solo se emplean si tienes dos capas vectoriales, por lo tanto, lo más recomendable es que realices un clip de un raster con un polígono (zonas de áreas protegidas), con ello tendrás un raster que se intercepta en tu polígono, ahora, como lo tienes reclasificado, puedes emplear la herramienta "RasterPixelCountStat", el detalle de su uso lo puedes ver aquí http://carbajallosa.blogspot.pe/2015/07/estadisticas-para-datos-espaciales-con_21.html.
saludos,
Publicar un comentario