
En esta oportunidad quisiera mostrarle parte de lo aprendido en el curso que llevé hace poco, la NASA - ARSET ofreció el curso "Introduction to Population Grids and their Integration with Remote Sensing Data for Sustainable Development and Disaster Management", siendo mi principal motivación para desarrollar esta publicación. El objetivo no es presentar todos los detalles técnicos que involucra el uso de datos en cuadrícula o de tipo ráster sobre población, para ello se recomienda acceder a los recursos brindados por el curso mencionado, existe buenas diapositivas y videos que explican muy bien las metodologías y los fundamentos técnicos sobre los que se sustentan. Mi objetivo es emplear las herramientas disponibles en el QGIS para acceder y visualizar los datos de población.
¿Porqué es importante saber cuántos somos y donde estamos?
De acuerdo al documento "Que nadie quede fuera del Mapa", disponer de datos de población fiables y actualizados puede suponer la diferencia entre la vida y la muerte para las personas que se encuentren en situación de crisis o que viven en regiones en conflicto. El documento resalta la importancia de saber dónde se encuentran las personas, qué condiciones enfrentan, qué infraestructura está disponible y a qué servicios básicos puede acceder. Los datos de población de tipo ráster que tienen como fuente a los datos de teledetección se han convertido en una herramienta necesaria para su acceso oportuno. Según Rebecca Gorin, en el contexto de la Pandemia por Covid-19, los datos de población en cuadrícula, juegan un papel importante en el seguimiento de la propagación del virus y garantizar que nadie se quede atrás.
¿Desde dónde podemos acceder a los datos?
Se recomienda acceder a https://www.popgrid.org/data-providers, desde donde podrán encontrar otros enlaces que les permite descargar los datos en función a diversos proveedores.

Otra manera es accediendo a las cuadros que presentan un resumen de las características de las distintas fuente de datos, desde la columna "Dataset" podrán tener acceso a sus respectivos enlaces.

Debido a las distintas fuentes de datos existentes, contar con una tabla resumen nos ayuda a conocer aspectos que los diferencian, y luego tener los criterios necesarios para seleccionar aquellos que nos pueden servir a nuestros objetivos. Del documento mencionado al inicio se extrajo una tabla resumen que podemos tenerlo como principal guía.

Además de los contenidos que ofrece el curso mencionado, para quienes deseen profundizar sobre metodologías y herramientas para estimar poblaciones, se recomienda revisar el artículo: Gridded population survey sampling: a systematic scoping review of the field and strategic research agenda. (https://doi.org/10.1186/s12942-020-00230-4).
Uso del QGIS - Plugin wpDatasets
Desde nuestro QGIS contamos con un Plugin Experimental denominado wpDatasets, el cual ayuda a los usuarios a descargar productos ráster del Proyecto Global WorldPop. Detalles del plugin lo pueden encontrar en su repositorio del código.

Una vez instalado, su manejo es muy sencillo, solo debemos activarlo y en el panel que nos aparece seleccionar los datos de población que requerimos descargar. Para el ejemplo seleccionamos los datos de población del 2020 en Perú. Si nos fijamos en la tabla resumen, WorlPop presenta datos desde el 2000 al 2020, emplea datos censales de GPWv4, tiene una resolución de 3 arc-segundos (100 m) y es acceso libre.


En caso requerimos una mayor resolución, podemos descargar para algunos países desde la fuente HRSL (High Resolution Settlement Layer), accediendo a las estimaciones de la distribución de población con una resolución de 1 arc-segundo (30 m aproximadamente), los que corresponden al año 2015. Las estimaciones de población se basan en datos de censos recientes e imágenes de satélite de alta resolución (0,5 m) de DigitalGlobe. Como ejemplo vamos a descargar los datos del país de México.

A continuación presentamos una imagen de la ciudad de México empleando el QGIS y con el apoyo del plugin "MapSwipe Tool".

Acceso desde Servicios WMS
Para complementar las opciones que tenemos para acceder a los datos de población, no podemos dejar de mencionar a los servicios de publicación de mapas bajo el protocolo WMS (Web Map Service). Se pueden mencionar :
- Socioeconomic Data and Applications Center (SEDAC), hospedado por el Center for International Earth Science Information Network (CIESIN). Incorporar desde el navegador de QGIS el siguiente URL: https://sedac.ciesin.columbia.edu/geoserver/wms.

El resultado que tenemos si accedemos al servicio GPWv4: Population Count 2020 es:

- WorldPop Spatial Data Infrastructure disponible desde una instancia de GeoServer. Debemos incorporar como servicio WMS: https://ogc.worldpop.org/geoserver/wpGlobal/wms. Lo que vamos a visualizar sería la misma información que obtuvimos al usar el plugin de QGIS wpDatasets. El servicio dispone de los mapas de población mundial del 2000 al 2020.

- Servicio ArcGIS REST, con los datos disponibles del CIESIN. Para tener acceso en el navegador de QGIS, ubicamos los servicios de mapas de ArcGIS, luego agregamos una conexión nueva con el URL: https://sedac.ciesin.columbia.edu/arcgis/rest/services/ciesin/popgrid_counts/MapServer.
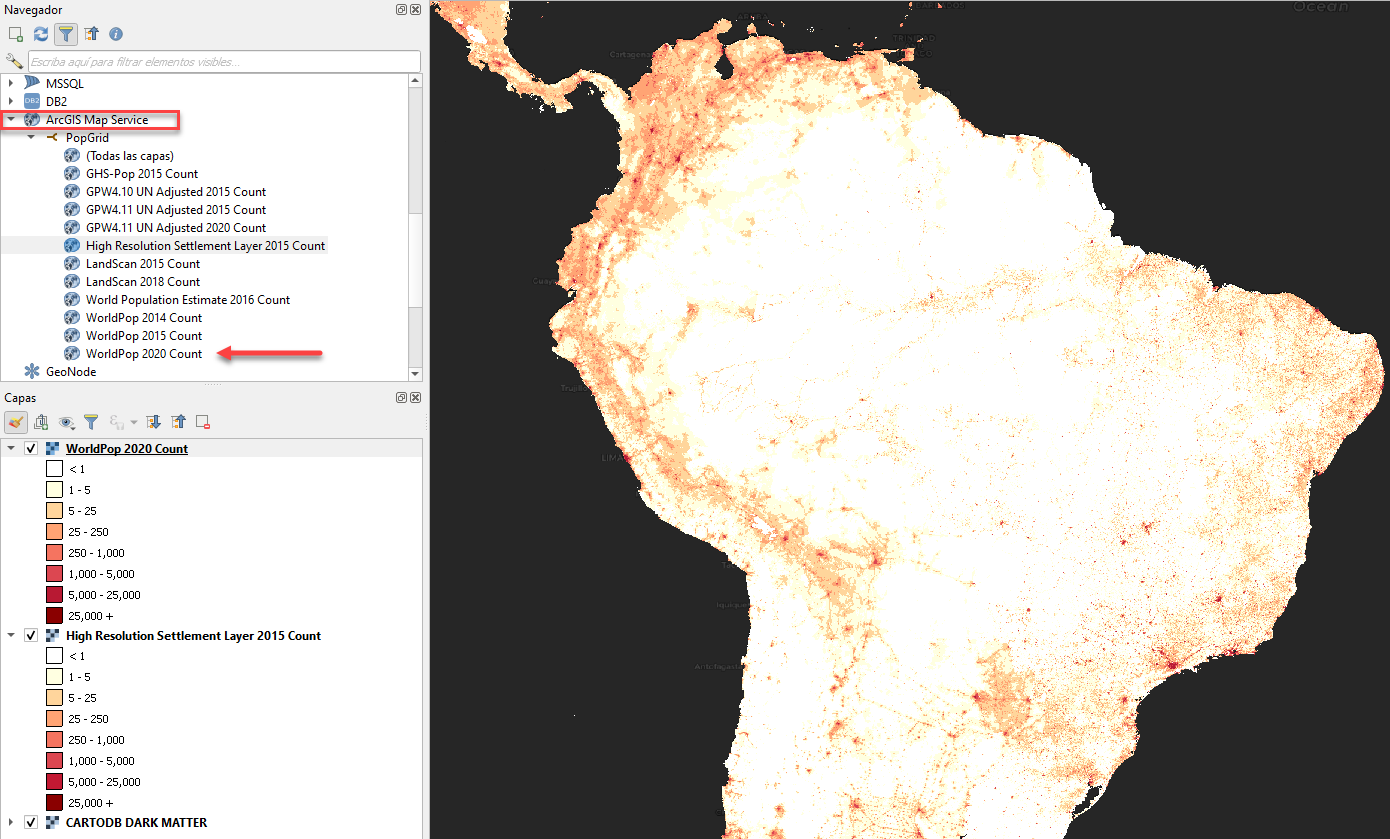
Hasta el momento hemos aprendido a emplear herramientas del QGIS para acceder y visualizar los datos de la población mundial desde diferentes fuentes. Se elaboró un video como recurso adicional y puedan apreciar el procedimiento descrito.
https://www.youtube.com/watch?v=dgutvhX2pqA